GIGABYTE G383-R80-AAP1 Topology
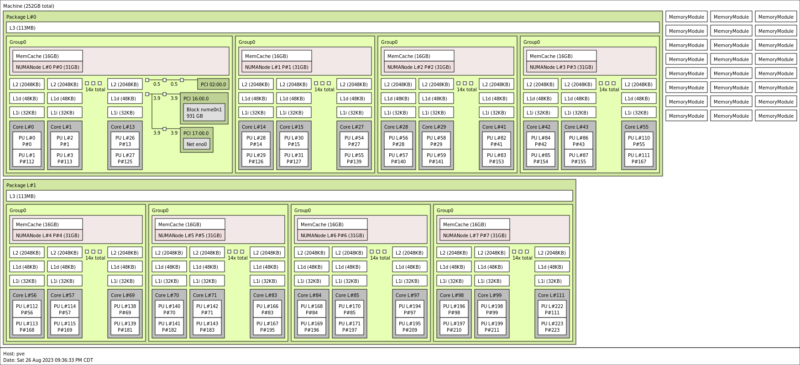
To help illustrate what we just saw in the hardware, here is the block diagram of the server:

The server is actually setup as a 4-way server much like a conventional 4-socket server. In fact, since AMD does not currently sell EPYC 4-socket servers, this is technically AMD’s 4-socket server solution. Each APU has connectivity for two PCIe Gen5 x16 slots. There are also two NVMe drive bays conencted via PCIe Gen5 to each APU, but APU0 has a Broadcom PEX89024 switch that also handles low-speed NIC connectivity to the 10GbE NICs.
The “ah ha!” moment that we had, albeit too late, was this topology diagram:

Being a bit more clear on what you are seeing, this is a 4-socket server, but each socket has 24 cores and the AMD CDNA 3 GPU attached. That means the server actually includes 512GB of HBM3 memory. There is no DDR5 memory here as the original thought was that additional memory would be added in MI300A/ MI300C platforms via CXL Type-3 memory expansion devices. Still, the domain of this server actually encompasses 512GB of HBM3 memory. If we were to compare this to the Intel Xeon MAX 9480 those CPUs only have 64GB of HBM2e and come in dual socket configurations. Although the direct competitor to Xeon MAX is probably the AMD MI300C, this is like having four HBM equipped CPUs and GPUs all on one system.
Putting that into perspective, Intel Xeon MAX would cache DDR5 to get around its limited CPU HBM that looks something like this, but there is not a GPU attached.
NVIDIA’s Grace Hopper GH200, is very different because instead of a uniform HBM pool, it has both HBM on the Hopper GPU and LPDDR5X on the Grace CPU pool.

AMD’s big advantage is really that they can put 512GB of HBM in a node where the CPU and GPU can access the same HBM3 memory pool. There is no caching or CPU to GPU transfers across a huge package.
It feels a bit strange, because I have heard AMD say this, but for me it was one of those things that I was told many times, but then to fire up a system and see it working provided a completely different level of understanding the point of MI300A. Perhaps that just points to me being slow, but I suspect I am not the only one who half-understood the MI300A impact until I saw it in a 4-socket system.
GIGABYTE G383-R80-AAP1 Management
Since this is using an industry standard ASPEED AST2600 BMC and management solution with features like HTML5 iKVM, it is fairly unremarkable from a management standpoint. That is actually the goal of a solution like this. Instead of wasting space here, you can see servers like our Gigabyte R113-C10 Review if you want to see that in action. Instead, let us get to something more interesting.
Notes About AMD Instinct MI300A
For those that skipped our topology section, this lscpu output of the system might be a bit mid-blowing.

On the GPU side we get 228 AMD CDNA3 compute units per APU. That compares with 304 on the AMD MI300X.

AMD’s performance lists the parts with the following performance levels:
- Peak Eight-bit Precision (FP8) Performance (E5M2, E4M3) 1.96 PFLOPs
- Peak Eight-bit Precision (FP8) Performance with Structured Sparsity (E5M2, E4M3) 3.92 PFLOPs
- Peak Half Precision (FP16) Performance 980.6 TFLOPs
- Peak Half Precision (FP16) Performance with Structured Sparsity 1.96 PFLOPs
- Peak Single Precision (TF32 Matrix) Performance 490.3 TFLOPs
- Peak Single Precision (TF32) Performance with Structured Sparsity 980.6 TFLOPs
- Peak Single Precision Matrix (FP32) Performance 122.6 TFLOPs
- Peak Double Precision Matrix (FP64) Performance 122.6 TFLOPs
- Peak Single Precision (FP32) Performance 122.6 TFLOPs
- Peak Double Precision (FP64) Performance 61.3 TFLOPs
- Peak INT8 Performance 1.96 POPs
- Peak INT8 Performance with Structured Sparsity 3.92 POPs
- Peak bfloat16 980.6 TFLOPs
- Peak bfloat16 with Strutured Sparsity 1.96 PFLOPs
Peak and actual are a bit different. We are going to do a bit more on the performance side in a future piece, but we wanted to focus more on the server in a server review. Something that is a bit strange to consider, is that if you had a 48U or 52U rack, and put 15-16 of these into it occupying 45U-48U, and if you had enough power and cooling to run them all at full speed, there is a good chance you could make the bottom end of the Top500 list.
One other item that is worth noting is that the APU actually has three video decode blocks for HEVC/H.265, AVC/H.264, V1, or AV1. If you wanted to create a video analytics platform, for example, this is actually supported which is something I did not realize before this. It may seem minor, but there have been a few AI accelerators that did not have video decoding which puts that burden on other components in a system. For most LLMs and HPC applications, this would not be an issue. On the other hand, if you wanted to run video through the system, you might care.
Next, let us discuss the power consumption.



{kind=link}
From the first page,
“Compared to the big 8x GPU servers, this is a relatively lower power machine which is fun to think about.”
Something else that’s fun to think about is a single one of these chips in HPC-dev workstations. Any indication that we might see something like a DGX Station (GB300 Grace Blackwell) from AMD?
Has the time come once again for serious fp64?
They can do this, but can’t make a high end gaming card. ♂️
I appreciate this article, but this is fun to think about instead, the SuperMicro GPU A+ Server AS -4126GS-NMR-LCC with 8 Instinct MI350 (8 x 288GB of HBM3E mem) and 2 EPYC 9005 series supporting 24 DIMM 6TB memory in 4U.